
Developers are used to writing tests with clear outcomes – either the test passes, or it doesn’t. There’s no ambiguity in the signal, unless the test itself is flaky and needs fixing.
But as AI slowly finds its way into our applications’ logic, this reassuring determinism is being forced to make room for an eccentric and somewhat unpredictable cousin – probabilism.
Probabilistic Workflows
Large language models (LLMs) are probabilistic by design – give one of them the same prompt twice, and you'll get two different answers. Sometimes, the difference is cosmetic. Other times, it's significant enough to flip a binary outcome.
This variability is fine when you're having a chat-like interaction with an LLM, but when these prompts are part of the workflow underlying your application’s logic, and the output dictates whether the application is working or not, it becomes a problem.
Since you can't rely on a single outcome, the trick is to reason about a distribution of outcomes instead. One bad answer isn't necessarily a bug – it might just be an occasional fluke. Conversely, one good answer isn't proof your prompt works – you might just have got lucky. A good way to assess the reliability of an LLM integration is to run it across a representative set of cases and look at aggregate results.
That, in AI-engineering parlance, is what evals are: evaluations of a model or workflow over a set of cases representative enough to make the averages meaningful. The term has been around for a while, but it’s more commonly used by people working on the model side. For application developers, evals are still a fuzzy concept – or at least that’s how it felt to me until recently.
And Then I Needed Them
Shortly after I started onboarding beta users onto PixelWatcher, I gave them the ability to flag false positives. And they did.
A quick refresher: PixelWatcher monitors webpages for changes you describe in natural language. Under the hood, each check is essentially an LLM call – give it two screenshots and a sentence describing what to look for, and it returns whether that change happened. The wording of the prompt, the schema of the response, the way the user's intent is woven into the request – every one of these decisions affects accuracy. And accuracy, for a monitoring service, isn't optional.
As I looked into the reported false positives and started tweaking the parameters to address them, I realised I had no way to tell whether any new version was consistently better than the previous ones, beyond eyeballing a few examples. Which, given the probabilistic nature of it all, was worth roughly nothing.
I needed proper evals.
PixelWatcher’s Eval Harness
Here’s another fuzzy word – harness. In this context, it basically means the infrastructure that runs the evals and collects the results. In PixelWatcher, I call it the sandbox. It’s got its own SQLite database and a bunch of CLI commands to run evaluations and render the results.
Each eval comprises three components:
- Scenario: a concrete test case. A baseline screenshot, a current screenshot, a change description, and an expected outcome;
- Experiment: a variation of the system prompt, user prompt, and response schema;
- Model: the LLM model the scenario and experiment are run against (Gemini, GPT, etc.).
Eval results are stored in the SQLite database and committed to Git for future reference.
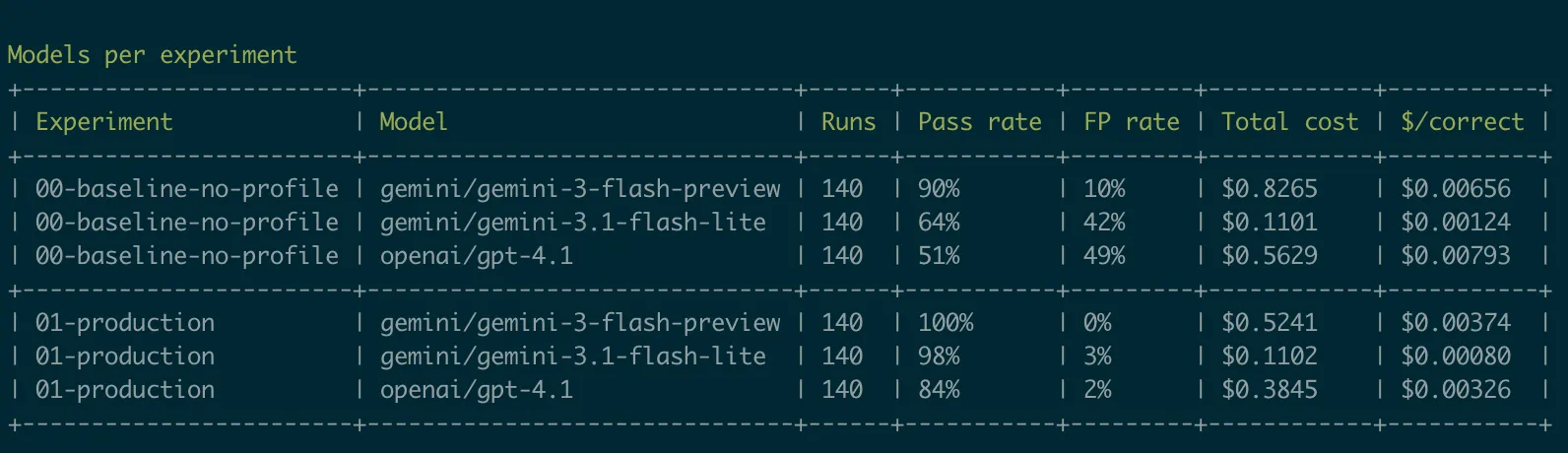
Example output – I also keep track of model pricing for cost estimates.
The most useful trick I've been using for this is importing real false positives as scenarios. When a user reports an hallucination, I export the relevant check's screenshots and metadata into a new scenario, annotate it with the correct outcome, and from that point on, every prompt or model I evaluate has to do at least as well on it. That alignment between what I'm measuring and what actually hurts the user is what makes the harness genuinely useful.
In Closing
There's something a bit unsettling about this whole picture. This industry largely built itself on the idea that the same input yields the same output – that bugs are always findable, and tests are always fixable. Evals, and the probabilistic systems they exist to measure, are an admission that some of the software we're writing today doesn't work like that.
And maybe that's not entirely a bad thing. Humans aren't deterministic either – they give different answers on different days. They get tired and change their minds. They constantly adapt to their environment.
Maybe determinism was always a limiting factor in what programs are able to do. Maybe some of our software is now becoming a little more like the people it's built for, and that is opening up a whole new set of possibilities.